
TL;DR
xarrayはラベル付き多次元配列のセットを扱うためのPythonパッケージで、PyDataによって開発されています。
Pythonにはもともと、多次元配列を効率的に扱うことのできるNumPy、ラベル付き1次元配列(系列データ)のセットを扱うpandasがあり、xarrayはpandasの多次元版と考えることができます。
xarrayは最初のリリースが2014年と比較的新しいですが、pandas側でもxarrayの利用を促しているようです。
実際、pandasには2次元配列のセットと扱うためのPanelと呼ばれるデータ構造がありましたが、xarrayの登場によってdeprecatedとなり、代わりにto_xarray()メソッドがpd.DataFrameに追加されています。
Panel was deprecated in the 0.20.x release, showing as a DeprecationWarning. Using Panel will now show a FutureWarning. The recommended way to represent 3-D data are with a MultiIndex on a DataFrame via the to_frame() or with the xarray package. Pandas provides a to_xarray() method to automate this conversion.
こうした背景の一方、xarrayはpandasほど使われていないのかなあという印象です。 例えば、Google Trendsによると、pandasとxarrayの検索数には大きな開きがあることが分かります。 xarrayを紹介している記事等も(日本語、英語ともに)pandasのそれと比べて圧倒的に少ないです。
実際問題、多次元配列というのは一般的には使われていない(使う必要がない)のかもしれません(例えば、Excelで表現できるデータであればpandasの範疇)。 しかし、研究分野の測定データは多次元に普通になり得ますし、データには測定時刻や座標等のラベルが付くことがほとんどですので、ラベル付き多次元配列というのは結構需要があるはずです。
そこで、この記事を含む一連の記事では、xarrayについて(自分の理解を深める意味でも)紹介します。 タイトルの通り、xarrayのデータ構造やメソッドはpandasのそれと共通する部分が多いので、これらを比較してまとめるのが良さそうです。 今回の記事ではxarrayのデータ構造のみの紹介です。
Scope
一連の記事を書く際に使用したxarray、pandas、およびNumPyのバージョンは以下の通りです。
- xarray: v0.12.1
- pandas: v0.24.2
- numpy: v1.16.3
これらは以下のようにインポートすることにします。
>>> import pandas as pd
>>> import xarray as xr
>>> import numpy as np
Data structures
Dataset & DataArray
以下の図はDatasetと呼ばれる、pandasでのDataFrame(pd.DataFrame)に相当するデータ構造を示したものです。
これは例えば、ある地域における気温と降水量のメッシュデータを、時系列で保存したものと見ることができます。
ここで、(x,y)はメッシュ座標、(lat, lon)は経緯度座標として、別々に表現されているような状況です。
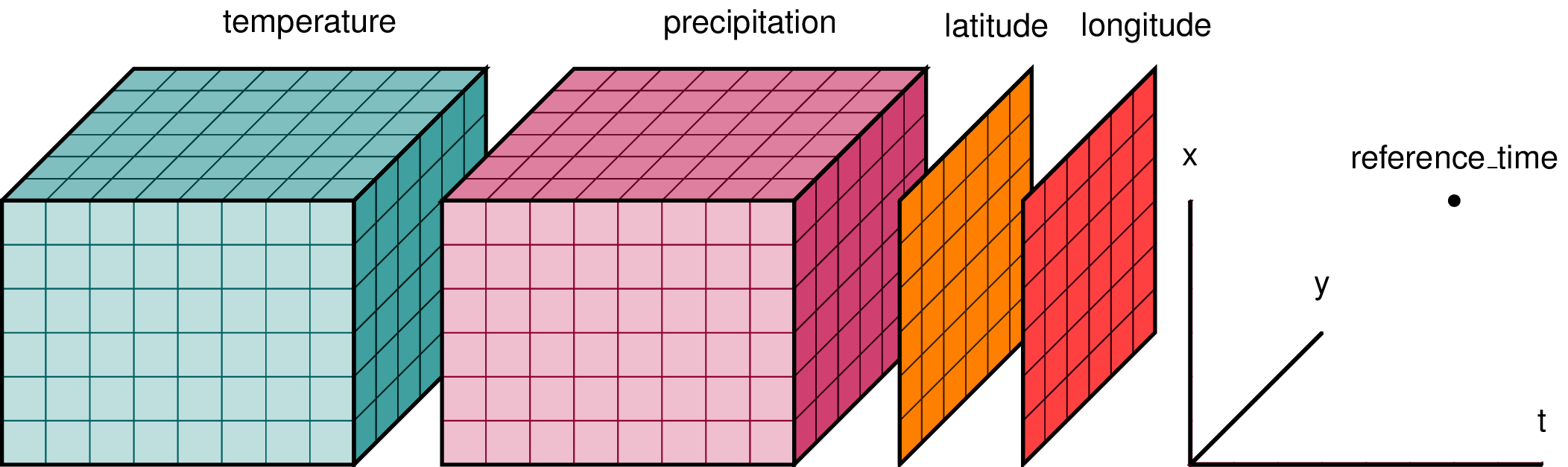
dataset-diagram.png
xarrayでは、pandasの系列データ(pd.Series)に相当するデータが多次元配列になり得ます。
この図では、全ての要素がそれに当たり、DataArray(xr.DataArray)と呼ばれます。
Coordinates & dimensions
pandasでは特定の系列データをラベル(pd.Index)に割り当てますが、xarrayでも同様に、特定の(複数も可)DataArrayをラベル化することができます。
この図では、気温と降水量が測定データなので、この2つ以外の全ての要素を割り当てるのが良さそうです。
ラベル化されたDataArray(s)は**coordinate(s)**と特別に呼ばれます。
一方、xarrayではラベル化によってオブジェクトが変化する(i.e., pd.Series→pd.Index)ことはなく、あくまでDataArrayのままです。
最後に、pandasにはない概念として、DatasetやDataArrayの各次元軸を規定する**dimension(s)**があります。 Dimensionsは軸名と軸の値を持つラベルとして、1次元のDataArrayで表現されます。 これらは、coordinatesとは別に生成することもできますし、1次元のcoordinatesを割り当てることもできます。 この図では、例えば(x, y, t)をdimensionsに割り当てるのが良いかもしれません。
これらの概念をpandasとの比較でまとめると以下の通りです。
| xarray | pandas | |
|---|---|---|
| 次元軸 | Dimension(s) (xr.DataArray) |
n/a |
| ラベル | Coordinate(s) (xr.DataArray) |
(Multi)Index (pd.(Multi)Index) |
| データ | DataArray (xr.DataArray) |
Series (pd.Series) |
| データセット | Dataset (xr.Dataset) |
DataFrame (pd.DataFrame) |
Examples
以上を踏まえ、実際にDatasetを生成してみましょう。
以下のスクリプトは、xarray documentationに記載されている例を元に、上の説明に合うように書き直したものになります。
Dimensionsはdimsとして軸名のタプルで、coordinatesはcoordsとして<name>: (<dims>, <value>)の辞書で表現されます。
# fix random seed
np.random.seed(2019)
# observed data
temperature = 15 + 8*np.random.randn(2, 2, 3)
precipitation = 10 * np.random.rand(2, 2, 3)
# coordinates
latitude = [[42.25, 42.21], [42.63, 42.59]]
longitude = [[-99.83, -99.32], [-99.79, -99.23]]
x = ['1', '2']
y = ['a', 'b']
t = pd.date_range('2014-09-06', periods=3)
reference_time = pd.Timestamp('2014-09-05')
# create dataarrays
dims = ('x', 'y', 't')
coords = {'latitude': (('x', 'y'), latitude),
'longitude': (('x', 'y'), longitude),
'reference_time': reference_time,
'x': ('x', x),
'y': ('y', y),
't': ('t', t)}
temperature = xr.DataArray(temperature, coords, dims)
precipitation = xr.DataArray(precipitation, coords, dims)
# create dataset
ds = xr.Dataset()
ds['temperature'] = temperature
ds['precipitation'] = precipitation
DataArray
まずはDataArrayを表示させてみます。
以下のように、NumPy arrayにcoordinatesがくっついた文字列が出力されます。
(x, y, t)に注目すると、名前の横に*が表示されていることが分かりますが、これらのcoordinatesがdimensionsとして割り当てられていることを表しています。
>>> temperature
<xarray.DataArray (x: 2, y: 2, t: 3)>
array([[[13.258568, 21.571643, 26.850222],
[25.654912, 12.105077, 20.484871]],
[[19.590091, 17.301821, 13.114926],
[22.627922, 1.482998, 12.240458]]])
Coordinates:
latitude (x, y) float64 42.25 42.21 42.63 42.59
longitude (x, y) float64 -99.83 -99.32 -99.79 -99.23
reference_time datetime64[ns] 2014-09-05
* x (x) <U1 '1' '2'
* y (y) <U1 'a' 'b'
* t (t) datetime64[ns] 2014-09-06 2014-09-07 2014-09-08
次に、coordinateにアクセスしてみます。 これも上で説明した通り、coordinatesもDataArrayであることが分かります。 (lat, lon)はdimensionsが(x, y)なので、元のDataArrayのcoordinatesのうち、(x, y)に含まれるcoordinates(lat自身も含む)が引き継がれています。
>>> temperature.coords['latitude']
<xarray.DataArray 'latitude' (x: 2, y: 2)>
array([[42.25, 42.21],
[42.63, 42.59]])
Coordinates:
latitude (x, y) float64 42.25 42.21 42.63 42.59
longitude (x, y) float64 -99.83 -99.32 -99.79 -99.23
reference_time datetime64[ns] 2014-09-05
* x (x) <U1 '1' '2'
* y (y) <U1 'a' 'b'
最後に、個々のDataArrayの持つNumPy arrayにはvaluesアトリビュートでアクセスできます。
>>> temperature.values
array([[[13.25856829, 21.57164284, 26.85022247],
[25.65491234, 12.10507702, 20.48487065]],
[[19.59009141, 17.30182133, 13.11492592],
[22.62792195, 1.48299758, 12.24045835]]])
Dataset
Datasetを表示させてみます。 DataArrayの一覧がdata variablesとして表示されています。 データが多様な次元を持つため、pandas DataFrameのような表形式のすっきりとした表示にはなりませんが、データ構造を理解していれば情報がまとまっていることが分かるかと思います。
>>> ds
<xarray.Dataset>
Dimensions: (t: 3, x: 2, y: 2)
Coordinates:
latitude (x, y) float64 42.25 42.21 42.63 42.59
longitude (x, y) float64 -99.83 -99.32 -99.79 -99.23
reference_time datetime64[ns] 2014-09-05
* x (x) <U1 '1' '2'
* y (y) <U1 'a' 'b'
* t (t) datetime64[ns] 2014-09-06 2014-09-07 2014-09-08
Data variables:
temperature (x, y, t) float64 13.26 21.57 26.85 ... 22.63 1.483 12.24
precipitation (x, y, t) float64 1.629 8.892 1.485 ... 5.783 2.993 8.372
最後に、個々のDataArrayには辞書形式でアクセスできます。
>>> ds['temperature']
今回はここまでです。 次回はDataset、DataArrayのメソッドをpandasと比較してまとめたいと思います。